Why AI features need proving before they ship (and why demos aren't enough)
A demo proves that an AI feature can look convincing once. Shipping requires stronger evidence: whether it works repeatedly, under real load, for the people expected to rely on it.

A convincing demo creates the illusion that an AI feature is ready. The harder question is what happens when you stop presenting and start operating.
Much of the current excitement around AI features follows the same arc: an AI company demos new technology with much fanfare, stakeholders get excited, and the conversation quickly jumps to "when can we ship this"? But between "it works in the demo" and "it works in production" is a gap that's larger (and more expensive) than most teams expect.
This gap exists because of something fundamental about Large Language Models (LLMs) that's easy to overlook. And it demands a different kind of validation before you commit.
The opacity of LLM capabilities
Many may not know this, but different LLMs from different companies (e.g. OpenAI, Anthropic, Google) are trained on very different data. Think about it: Google has access to 14.8 billion YouTube videos and petabytes of user data from Google Drive and Google Photos. No wonder their Gemini models are strong at processing PDFs and audio/video content. Similar dynamics likely apply to Anthropic; whatever they trained Claude on probably contributed to it being good at coding.
So while different LLMs can feel interchangeable, they're not. Ted Chiang's description of LLMs as a "Blurry JPEG" captures this well: these systems compress and reconstruct patterns from their training data in new and novel ways, but their strengths and blind spots vary in ways you won't notice until you hit them, since we have no clue what they are (or aren't) trained on.
And it's not just the models. The tooling and products around them differ too. Some AI products only generate text. Others can execute code, browse the web, or call external APIs. A feature that works beautifully when backed by one model-and-tooling combination might fail quietly with another.
This is the first problem anyone building an AI feature should internalise: you cannot predict what a model will be good or bad at from the outside. You have to test it on your specific task, with your specific data, under your specific conditions. There is no shortcut.
When output looks right, but isn't
The dangerous failure mode of LLMs isn't bad output. Bad output is obvious; you read it, it's wrong, you move on. The dangerous failure mode is good-looking output that's quietly wrong.
I ran into this recently when testing AI tools for research survey analysis, by feeding survey responses into a capable model and asked it to produce an insights report. What came back looked genuinely impressive: tables, an executive summary, percentage breakdowns, recommendations. Formatted cleanly. Read professionally. The kind of output you glance at and think, "Maybe the new models really are getting better".
It was only when I started double-checking the numbers that I noticed: the percentages weren't right.
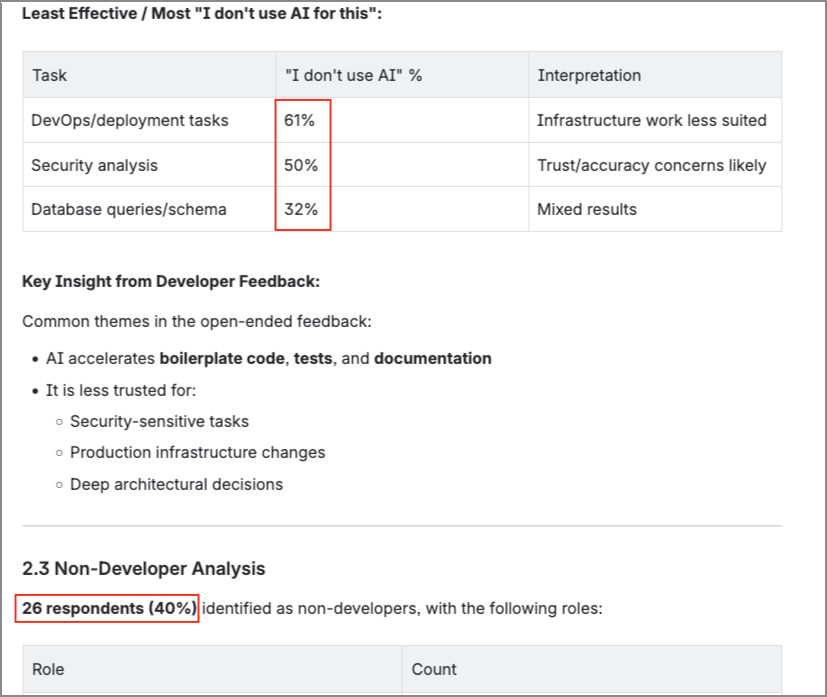
The draft said 26 non-developer respondents. The actual number was 23. Another percentage was off by four points. While the overall narrative was still accurate, such gaps would've been factually embarrassing if someone downstream ran the numbers themselves.
None of this should have surprised me. LLMs are architecturally bad at arithmetic; they're simulating calculation through pattern-matching, not actually computing. But what did surprise me was how close I came to missing it. The report didn't read like something that had errors. The formatting was clean. The language was confident. Everything about the presentation signaled "this was done carefully".
That's the failure mode worth designing around. The real risk is that the AI got it wrong and you didn't notice, because the output was polished enough to pass a casual review.
If the model's failure mode is invisible by default, then your feature needs to make it visible by design.
Proof of Concept - does it actually work?
In traditional software, a Proof of Concept (POC) answers a straightforward question: can we build this? Can the systems integrate? Can the architecture handle the load? Can the team execute the design?
When the feature involves an LLM, the build question is trivial, since wiring an API call to a model is easy. The harder question is: can this model do this specific task, with your specific data, at a quality level you'd actually ship?
An AI POC needs to test for things that differs from traditional POCs:
- Accuracy. Does the model get the facts right? Not once, but repeatedly, across varied inputs.
- Consistency. Does it produce similar quality every time, or does output quality swing unpredictably?
- Edge cases. What happens with messy data, unusual inputs, or ambiguous instructions?
- Failure modes. When it fails, how does it fail? Silently and confidently? Or in a way users can detect?
A demo shows the best case. A POC maps the failure surface. It's designed to find the boundaries of what the model can handle, so you know where you'll need guardrails, fallback logic, or a different approach entirely.
"But what if it fails the POC? Do we just shelve the idea?"
Not necessarily. And this is where AI POCs differ most from traditional ones: the results have a much shorter expiration date.
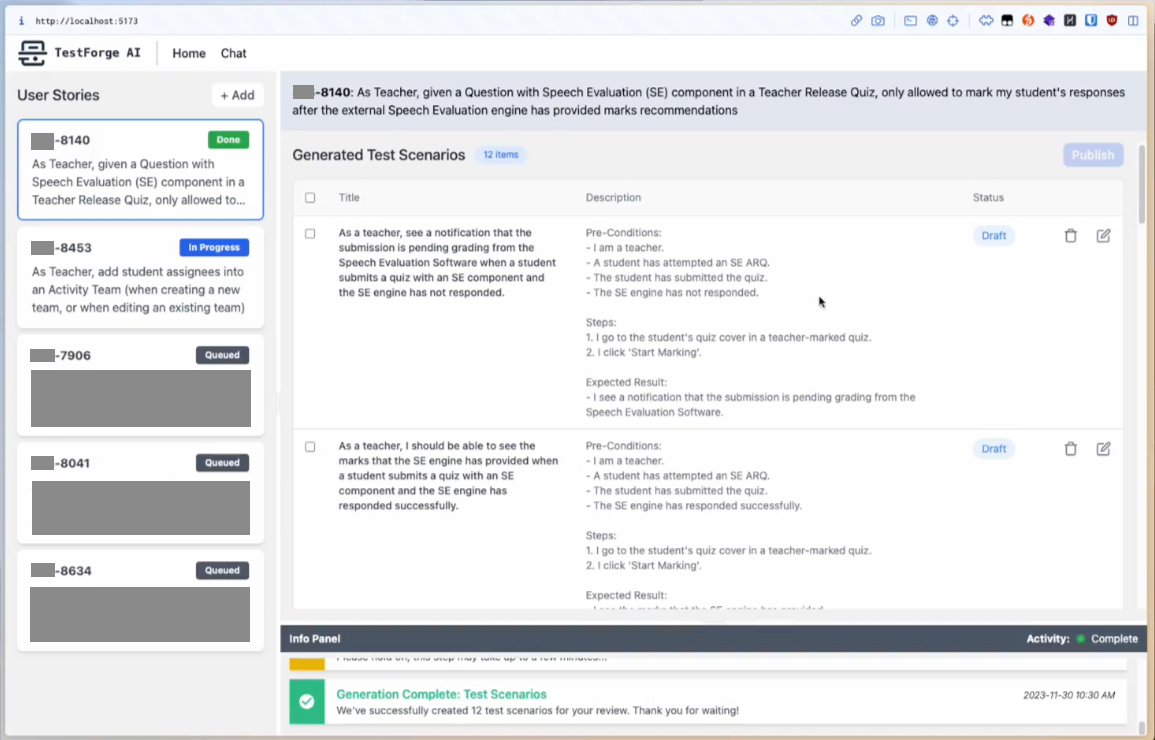
In 2023, as part of Google AI Trailblazers, my team experimented with using LLMs to generate test scenarios from requirements. It didn't work well enough to ship. The models at the time had small context windows, limited agentic capability, and the RAG technology we needed for feeding in project context was still immature. The POC failed... correctly.
But "failed in 2023" doesn't mean "failed permanently". The models improved. Context windows expanded. Agentic tooling matured. The same idea, tested again with today's capabilities, might pass. We've seen the same trajectory with AI-assisted coding: the gap between what was possible eighteen months ago and what's possible now is enormous.
A POC for an AI feature isn't a verdict. It's a timestamp. It tells you whether the technology can do this right now, with the models and tooling available today. That answer will change. The discipline is knowing when to retest.
Proof of Value - is it actually worth it?
A working POC answers "can the model do this?" It doesn't answer the harder question: is using the model for this task actually better than the alternative?
This is what a Proof of Value (POV) addresses. Where a POC validates feasibility, a POV validates usefulness. Does anyone actually care that it works?
I learned this distinction the hard way. In 2024, I built Pete, an internal RAG-based AI tool that could answer questions by searching across company documentation. One of the first use cases was HR knowledge: policies, leave procedures, onboarding guides. The POC was clean: the model retrieved relevant articles, synthesised accurate answers, handled follow-up questions. It worked.
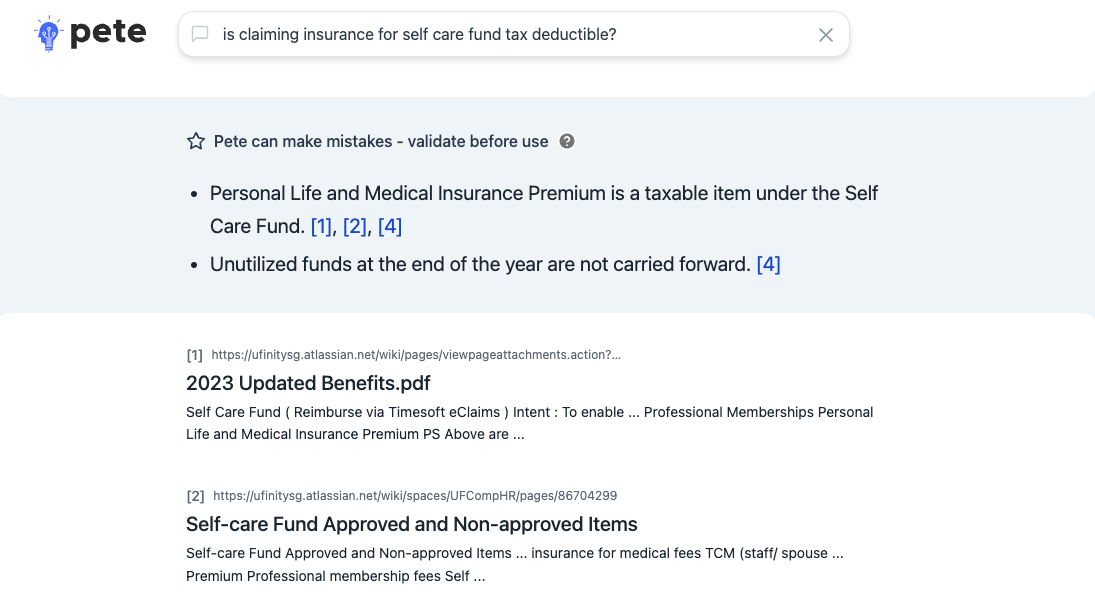
But, it also showed an uncomfortable truth: the usage was low.
While the answers were adequate, people just didn't have HR questions often enough for the tool to become a habit. The feature was accurate but used infrequent. It passed the POC and failed the POV.
Meanwhile, the same underlying technology, RAG over internal documents, applied to a different context told a completely different story. When I connected Pete to software project documentation and integrated it with the development team's day-to-day chat software, demand was immediate. Analysts & developers queried it constantly. It lived where the work happened, answered questions people had every day, and saved real time on tasks that were genuinely painful.
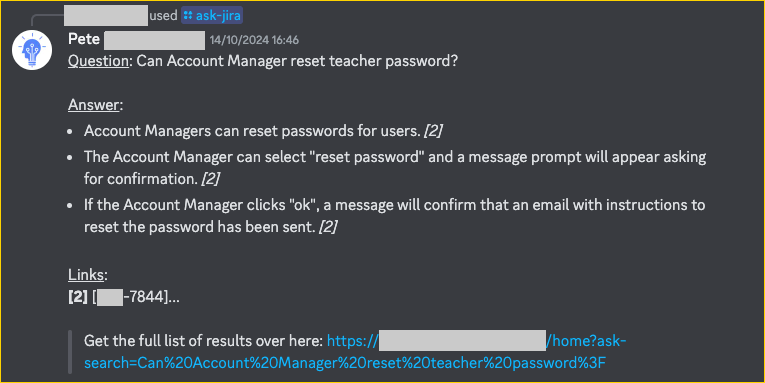
Same technology. Same architecture. One use case gathered dust. The other became relied upon.
The difference came down to fit. The HR use case was an "easy win" that nobody actually needed to win very often. The project docs use case solved a friction point people hit daily. A POV helped to surface his before investing in polishing the wrong feature.
A POV forces you to ask the uncomfortable questions:
- Do people actually have this problem frequently enough to justify the feature?
- Is the time saved greater than the time spent verifying, correcting, and maintaining?
- Does the feature live where the work happens, or does it require people to change their workflow?
Many AI features die in this gap. The demo wows stakeholders. The POC confirms feasibility. But the value, when measured, shows that the problem isn't painful enough, the solution isn't trusted enough, or the overhead eats the savings.
Demand, load, and the pressure to ship
There's a compounding pressure that makes POC and POV even harder to defend: AI features are in hot demand.
Stakeholders want them. Users expect them. Competitors are shipping them. The incentive is to move fast, to get something out the door, and to iterate later. And because AI demos are so convincing, "iterate later" often sounds reasonable.
But when you do ship (assuming the POC and POV check out), the operational profile of AI features is fundamentally different from traditional features:
- Token costs compound. Every interaction with an LLM is billed by token. Longer conversations cost more because the entire history gets re-sent with every message. A feature that's popular is a feature that's expensive (which you need to plan for).
- Rate limits constrain throughput. Your model provider allocates you a budget, measured in requests or tokens per time window. High demand can mean users hitting limits and waiting, unless you've planned capacity in advance.
- Latency varies. LLM response times aren't constant. They depend on model load, prompt complexity, and output length. Users expect consistency. LLMs don't guarantee it.
- Quality can drift. Model providers update their models. A feature that passed your POC last month might behave differently after a model version change. Ongoing monitoring isn't optional, but a requirement.
Most traditional features don't need this level of operational attention. AI features do, because the "engine" powering them is a black box that is improving at rapid pace, and that's not something you can control.
What actually ships
There's a version of this argument that sounds like caution for caution's sake. Slow down. Test more. Don't ship until you're sure. In a landscape where competitors are moving fast and stakeholders want AI features yesterday, that can feel like a luxury.
A traditional feature that has a bug can be patched. An AI feature that produces confidently wrong output erodes trust in a way that's much harder to recover from. And a feature that works but nobody uses (like my HR knowledge assistant experiment) is a quieter kind of waste that, when applied to the wrong scale, can burn budget and credibility.
What I've landed on isn't a framework. It's three questions:
- Can the model actually do this? (POC, and the answer has an expiration date.)
- Does anyone actually need this, enough to use it? (POV, and "easy win" is not the same as "valuable")
- Can we operate this sustainably? (Cost, load, monitoring, trust)
Every stage teaches you something. A failed POC tells you what the technology can't do yet, and gives you a timestamp for when to try again. A failed POV tells you where the real pain points are, which sharpens your aim for the next attempt. These are cheap lessons.
But the further along you go before discovering the problem, the more it costs. Not just in dollars, but in user trust and team momentum.
The models will keep getting better. Things that fail today will work tomorrow. And every POC you run, even the ones that fail, builds your team's intuition for what works, what's close, and what's still out of reach.
The discipline isn't in knowing the right answer, it's in knowing to ask the right questions.