How you talk to AI is itself a design decision
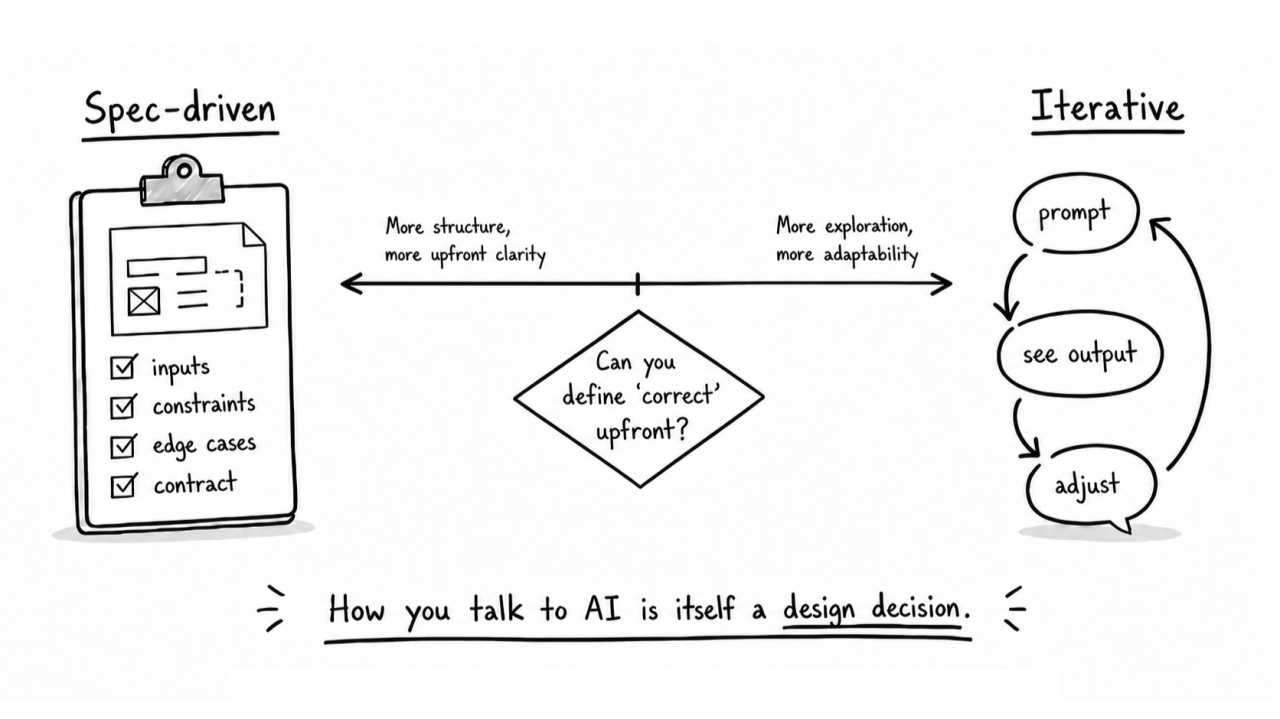
Spec-driven and iterative prompting are both design choices. The question is where quality judgment belongs: upfront in a contract, or later through feedback.
In a previous article, I wrote about AI as a universal translator and how it amplifies whatever intent you bring. I left a question open: how should you communicate that intent? I have been thinking about this since, and I believe the answer sits on a spectrum that most people do not consciously choose a position on.
On one end, you define everything upfront. Inputs, outputs, constraints, edge cases, expected behaviour. The AI receives a near-complete blueprint and builds against it. I think of this as spec-driven development.
On the other end, you start with a rough direction and refine through a chain of prompts. Each AI response reveals something about the problem, and you adjust based on what you see. The solution emerges through conversation. I think of this as iterative development.
Both work. Neither is always right. The choice depends on the problem.
The signal is in the feedback loop
The most useful question I have found is: how much of the quality judgment depends on seeing the output versus defining a contract?
Some problems have clear correctness criteria. An API either returns the right data or it does not. A data model either represents the domain accurately or it breaks under real usage. An authentication flow either meets the security requirements or it fails. These problems respond well to specification. You can define what "correct" looks like before building, and the AI can execute against that definition with minimal drift.
Other problems resist upfront definition. You know quality when you see it, but you cannot fully describe it in advance. The balance between information density and clarity on a UI screen. The rhythm of a user flow. Whether a page feels right or just looks complete. These problems respond better to iteration, because the feedback loop depends on judgment that only activates when something exists to react to.
Frontend taste, backend contracts
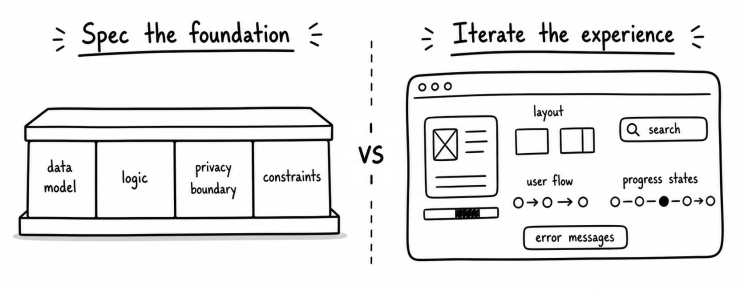
This maps, roughly, onto a divide most developers already feel. Frontend work tends to carry more of what I think of as human taste. Spacing, visual weight, the way a layout guides attention, the moment a page crosses from dense to cluttered. These qualities are hard to pin down in a written spec. You can describe a button's behaviour, but the feel of the interaction around it emerges through seeing and adjusting.
Backend work more often lives in contracts you can define before building. Input shapes, output formats, error handling, data relationships, performance constraints. The correctness criteria sit closer to the surface, which makes specification more effective as a starting point.
This is not a clean divide. A recommendation algorithm sits on the backend but might need exploratory iteration to get the weighting right. A design system component sits on the frontend but benefits from tight specification so that it stays consistent across contexts. The axis is not about where code runs. It is about how much of the quality judgment can be stated before building versus how much requires seeing the result first.
The waterfall and agile parallel
Software development has been working through the same tension for decades, just at a different speed.
Waterfall assumed you could define everything upfront: requirements, then design, then implementation, then testing. It worked when requirements were stable and well-understood. It failed when user needs were unclear, when the problem only revealed itself during building, or when taste mattered more than correctness.
Agile emerged as a response. Shorter cycles, continuous feedback, planning that adapted as understanding grew. It worked when learning happened through building. It introduced its own costs: architectural drift, inconsistency, and the gradual loss of big-picture coherence when short-term iterations accumulated without a larger frame.
AI-assisted development compresses both patterns dramatically. Spec-driven prompting is waterfall compressed into minutes. You still front-load all the thinking, but execution is basically instant. Iterative prompting is agile compressed into a single working session. You still discover through doing, but each cycle takes minutes rather than weeks.
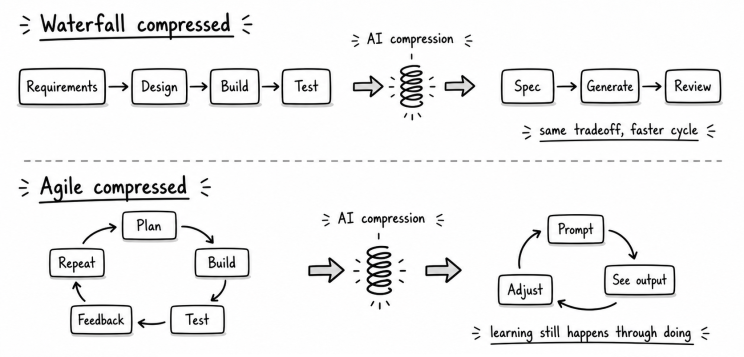
The compression changes the speed. The underlying tradeoffs remain. Birgitta Böckeler, after testing several spec-driven development tools hands-on, observed that small iterative steps still tend to outperform verbose upfront specifications, particularly when the tools cannot reliably pick up on everything in a large context window. Her conclusion was direct: she would rather review code than review markdown files. The problems that made pure waterfall fail do not disappear just because the cycle is faster.
The reverse also holds, but the failure mode is different. Agile's weakness was strategic: short iterations accumulating without a larger frame. Iterative prompting has a structural weakness on top of that: context rot. Every iteration adds tokens to the context window. As the window fills, the attention mechanism spreads thinner across all prior content. Each subsequent output is measurably worse than the last, not because any single prompt was bad, but because the model's ability to attend to everything before it decays with every round. The degradation is cumulative and mechanical, and applies to AI coding agents as well, such as Claude Code.
Two practitioners, one spectrum
The clearest illustration I have seen of this spectrum comes from watching how two experienced developers work with AI, each starting from a different end but arriving at a similar conclusion.

Matt Pocock, a TypeScript educator and toolmaker, built an agent skill called /grill-me. Before any code is written, it instructs the AI to interrogate him about every aspect of his plan, walking down each branch of the decision tree, resolving dependencies between decisions one by one. He has described sessions where the agent asked 40 or 50 questions before a single line of code was produced. The output of these sessions feeds into a specification document, which then becomes the blueprint the agent builds against. His reasoning is straightforward: the most common failure mode in software development is misalignment between what you meant and what gets built. The grilling session closes that communication gap before implementation begins.
But Pocock does not grill everything. He skips it for single-step tasks, reversible experiments, and changes where the decision space is already fully constrained. The tool exists precisely because he recognises that some problems benefit from exhaustive upfront definition and others do not.

Simon Willison, co-creator of Python Django, works from the other end. His preferred definition of an AI agent is something that runs tools in a loop to achieve a goal. His practice centres on designing that loop well: small testable chunks of logic, immediate execution, verification, and feedback into the next prompt. He chooses his core AI tools based primarily on whether they can safely run and iterate on his code.
But Willison is not working without structure. He treats test-first development as the foundation that makes iterative loops safe. Tests give the agent clear signals about whether its changes are correct. And he holds a firm line: he will not commit any code he cannot explain to someone else. The iteration is fast, but the quality gate is strict.
Both practitioners have found their way toward the middle. Pocock starts with exhaustive specification but knows when to skip it. Willison starts with iterative loops but anchors them with tests and a hard rule about understanding. Neither treats their approach as universal.
Hybridisation in practice
Most real work sits somewhere in the middle, and often the right approach varies within a single project.
When I built the Skills Framework Explorer, I wrote detailed specifications for the data model and the logic that mapped roles to skills and proficiency levels. That part had clear contracts: the data either matched the source accurately or it did not. But the search and comparison interface went through several rounds of iterative prompting. I needed to see the layout before I could judge whether the information hierarchy worked for users who were comparing two roles side by side.
The pattern that keeps showing up: spec the constraints and architecture, iterate on the experience and interface. Define the data model upfront. Discover the layout through conversation.
This hybrid also hedges against context rot. A specification that lives outside the conversation, in a file or a pinned reference, keeps foundational decisions from competing for attention with dozens of later prompts. The model can re-read a spec. It cannot reliably recall a constraint from 40 iterations ago.
Choosing consciously
A rough heuristic I have landed on: if I would be frustrated by the AI interpreting a requirement differently from what I meant, I write the spec first. If I can evaluate the output quickly and adjust in the next prompt, I iterate.
This is a working test, not a rule. But it has been more useful to me than defaulting to one mode out of habit. The default matters because AI will comply either way. It will build against a loose prompt just as willingly as a tight specification. The difference shows up in the output. Spec-driven work tends to fail through rigidity: the spec was wrong and the AI followed it faithfully. Iterative work tends to fail through context rot within a session, and through context fragmentation across sessions, as decisions and constraints scatter across conversations the model cannot see.
Both failure modes are more costly now that building is fast. A wrong spec produces a finished but misguided tool in an hour. An undirected prompt chain produces a tangled and fragmented codebase in an afternoon. Recognising which failure you are more exposed to, given the specific problem, is what makes the choice productive rather than accidental.
I am still calibrating where different kinds of problems sit on this spectrum. But I have stopped treating the question as incidental. How you talk to AI shapes what it builds, and that choice deserves at least as much thought as the intent behind it.